LLMOps Tools 2026: A Founder's Honest Take on What Actually Matters

Five platforms. One major acquisition. And most teams are still running their AI stack like it's a completely separate discipline from the rest of software engineering.
Every LLMOps comparison you've read is a feature table. Those tables are useless for making decisions. The question that actually matters: does this tool fit into the way your team already builds software, or does it require a parallel set of tools, processes, and habits?
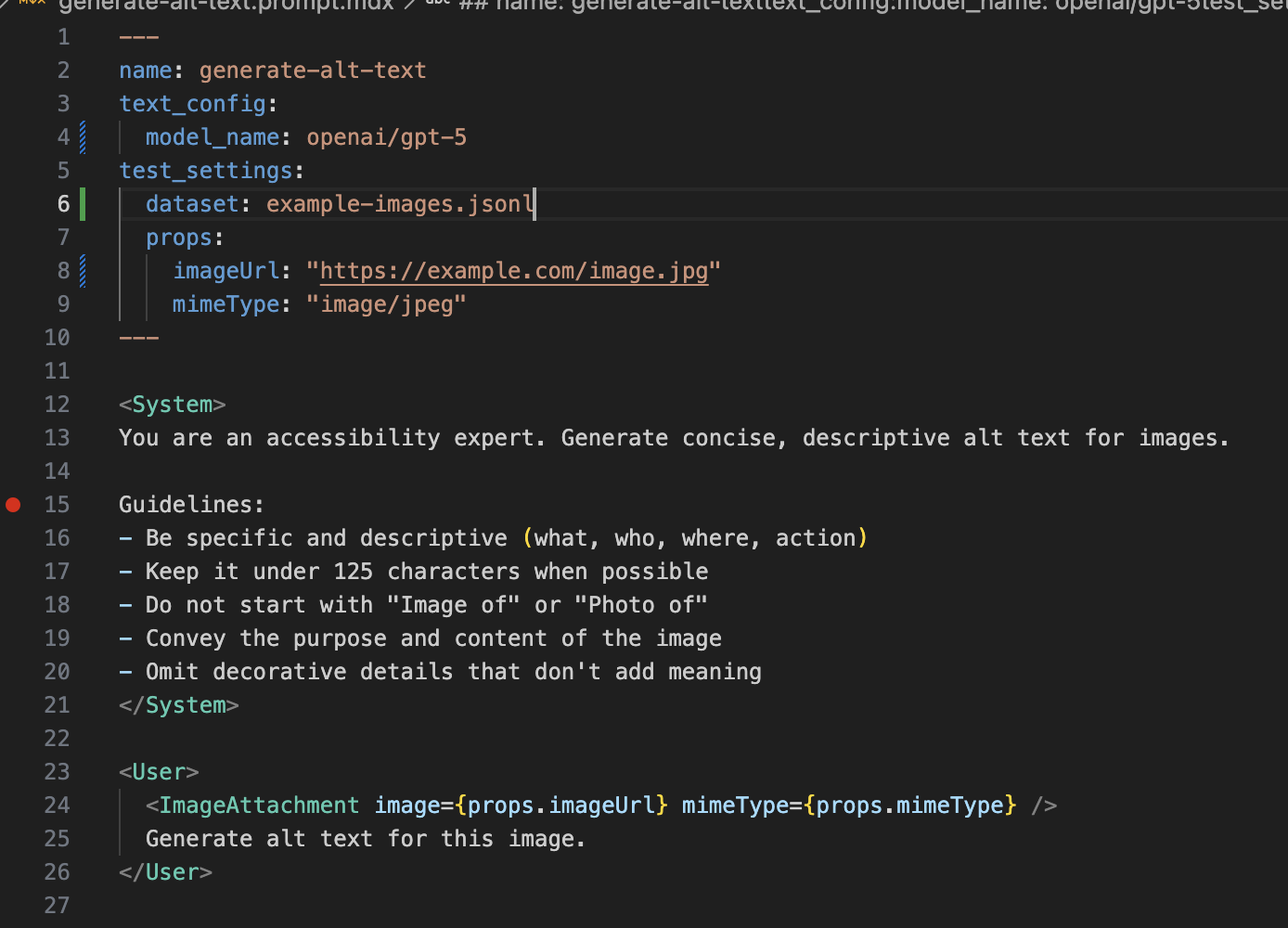
We built AgentMark, one of those five platforms, so take everything here with that in mind. Our conviction: prompts, datasets, and evals belong in git, the same way application code does. Same editor, same branches, same PRs, same CI. That belief shapes this entire comparison.
#What changed in LLMOps tools this year
#Agents replaced the chatbot
Most teams aren't wrapping a single API call anymore. They're building multi-step workflows where agents call tools, branch on decisions, retry on failure, and orchestrate sub-agents. A trace that shows "prompt in, completion out" is like reading the last page of a mystery novel. You know the result but not how it got there.
Every tool on this list now says "agent tracing" on their homepage. The difference is depth. Some show a flat list of requests.
Others show a full span tree with parent-child relationships, tool call arguments, retry logic, and latency breakdowns per step. When your agent hallucinates on step four of seven, one view helps you fix it in minutes. The other leaves you reconstructing the timeline manually.
#OpenTelemetry won
This one is settled. OTEL is how you instrument AI workloads in 2026. Arize built on it from the start with their OpenInference standard.
New Relic launched an OTEL-compatible AI agent platform this February. The tools that started with proprietary SDKs are all adding OTEL export now, some faster than others.
Why does this matter practically? When you switch trace backends (and you will), re-instrumenting is the tax nobody budgets for. OTEL means you switch backends without changing your code. If a tool still requires a proprietary-only SDK, you're paying a cost you won't notice until you try to leave.
#Real money showed up
ClickHouse acquired Langfuse as part of a $400M Series D in January. Braintrust raised $80M at an $800M valuation in February, backed by ICONIQ, a16z, and Greylock. LangChain shipped Agent Builder to GA. These are no longer weekend projects and angel rounds.
Big raises change incentives. Enterprise features get prioritized. Free tiers get scrutinized. If your workflow depends on a generous free plan, think about that before you commit, not after.
#LLMOps tools in 2026: the honest breakdown
#Arize AX
Arize AX is the tool I'd pick if my team lived in Jupyter notebooks. It's built on top of Phoenix (their open-source library, 8,700+ GitHub stars, Elastic License 2.0), OTEL-native from day one with their OpenInference standard. The platform starts free (25K spans/month), $50/month for Pro (50K spans), and custom pricing for enterprise with self-hosting options.
What sets it apart: embedding visualizations for retrieval debugging, an Evaluator Hub with versioned evaluators (including Tool Selection and Tool Invocation evaluators for testing whether agents pick the right tools with the right parameters), and framework support across LangGraph, Vercel AI SDK, Mastra, CrewAI, LlamaIndex, and DSPy. The deepest observability stack in this space.
Arize is Python-first. TypeScript support exists but the experience is rougher. Prompt, dataset, and eval management lives in the UI. Phoenix can be self-hosted under ELv2, but you can't offer it as a managed service. If that matters for your business model, read the license.
Best for: Python teams whose debugging starts in notebooks. Deepest observability stack available, with a free tier that's generous enough to evaluate seriously.
#Braintrust
| Detail | Value |
|---|---|
| Funding | $80M Series B, $800M valuation (ICONIQ, a16z, Greylock) |
| Notable customers | Notion, Stripe, Vercel, Zapier |
| Free tier | 1M trace spans + 10K scores/month, unlimited users |
| Pro | $249/month platform fee + usage |
Braintrust takes evals more seriously than anyone else here. 25+ built-in scorers. A "Loop" AI assistant that generates custom scorers from natural language descriptions in about ten minutes. That's a day of Python scripting compressed into a conversation.
At their Trace conference in February they shipped Brainstore (purpose-built for querying AI traces, 23x faster full-text search than general-purpose alternatives) and multimodal trace views that render images, video, audio, and PDFs directly inside traces. Nobody else does that yet.
The trade-off is platform dependence. SDKs are open-source and they offer hybrid self-hosting (you host the data plane, they host the control plane). But there's no fully self-contained option. Notion, Stripe, Vercel, and Zapier are all customers, so the platform is clearly production-grade. If OTEL portability or full data ownership matters to you, that's where you'll feel it.
Best for: Eval-heavy teams that want the most sophisticated scoring infrastructure available. The Loop assistant and 25+ built-in scorers are unmatched.
#LangSmith
Model your trace costs before you commit. A ticket-routing agent handling 50,000 conversations a month, each producing 30-40 spans, generates 1.5M+ traces. LangSmith gives you 5,000 free. On the Plus plan, base traces run $0.50 per 1,000 overage (14-day retention) or $5.00 per 1,000 with 400-day retention. A five-person team at 1.5M traces could hit $800+/month they didn't budget for.
The product can earn that cost. 260M+ monthly Python downloads between LangChain and LangGraph. Agent Builder went GA in January with MCP server support. An Insights Agent automatically analyzes traces to detect failure modes. They've added multi-framework support (OpenAI SDK, Anthropic SDK, Vercel AI SDK), so it's no longer just a LangChain tool.
The lock-in question: prompts, datasets, and evals live in LangSmith's UI, not in your repo. No branching, no PR reviews on prompt changes, no way to test a risky edit in isolation before it hits production. If your team is already deep in LangChain, the ecosystem gravity is real and probably worth the trade-off. If you're framework-agnostic, model the costs first.
Best for: Teams already in the LangChain ecosystem. The largest community, the deepest framework integration, and features like Agent Builder and Insights Agent that nobody else has. Just model your trace costs before you commit.
#Langfuse
22,400+ GitHub stars. 26M+ SDK installs per month. 63+ Fortune 500 companies. When you hit an edge case at 2am, a community that size has probably seen it.
ClickHouse acquired Langfuse as part of a $400M Series D, and the team hasn't coasted. They've shipped a full CLI, observation-level evaluations, dataset versioning, and an MCP server with write capabilities. Both teams say the MIT license stays. Worth watching, but the recent output is genuinely strong.
Langfuse is dashboard-first. The CLI is an access layer on top of the UI, not the other way around. That works great for teams who prefer a visual workflow. Where it gets harder: 50+ prompt files, datasets evolving alongside them, PR reviews on changes, CI gates on evals. Branching a set of experimental prompt changes in a dashboard or rolling back a dataset to last Tuesday's version. The dashboard-first model wasn't built for those workflows.
Best for: Teams that want the largest open-source community and a UI-driven workflow. MIT-licensed, massively adopted, and actively shipping post-acquisition.
#AgentMark (us)
AgentMark was built to solve a specific workflow frustration: prompts, datasets, and evals living in a completely separate set of tools from the rest of our code. We wanted the same git workflow for our AI stack as we had for our application code. The dashboard is the collaboration layer, not the source of truth.
AgentMark is a hosted platform with a dashboard for tracing, experiments, and prompt editing. Domain experts and PMs can edit prompts in the UI; changes sync back to git. You get the same observability dashboard, trace viewer, and experiment management you'd expect from any tool on this list.
What's different is what happens underneath. Prompts are MDX files. Datasets are JSONL. Evals are functions. Everything in the dashboard is backed by files in your repo. That means version history via git log, rollback via git revert, isolated experiments on branches, and PR reviews before anything touches production. Domain experts and PMs can edit prompts in the dashboard; those changes sync back to git as commits, so non-engineers can contribute without losing the review process. Environments are branches, or handled through promotions.
Evals run in CI and block merges the way tests do. The GitHub Action (agentmark-ai/eval-action) runs on every PR, compares each test case against the baseline from the base commit, and fails the check with per-case annotations in the same PR panel as your jest or vitest runs. There are two independent gates: an absolute pass-rate floor and a regression gate that fires when individual cases score worse than they did before, so a prompt change can't quietly degrade ten specific cases while keeping the overall pass rate steady. The same JUnit output works on GitLab and any other CI platform.
Tracing is OTEL-native. TypeScript and Python are both first-class. Use the observe() helper to wrap any function and get automatic input/output capture with span kind tagging (agent, tool, retrieval, guardrail) without touching your instrumentation setup. We also ship an MCP server that gives coding agents like Claude Code and Cursor direct access to your traces, datasets, and evals. The entire fix loop becomes one instruction:
"Find me the failing traces, classify why they failed, create an eval for them, add the failing cases to a dataset, fix them, and open a PR when you're done. Make sure CI passes."
That works because the coding agent has access to the same files, traces, and datasets you do. No copy-pasting between tabs. No manual handoff from trace viewer to editor to eval runner.
A few other things worth knowing. The Playground lets you run up to 6 prompt variants side by side: different models, temperatures, rewrites. Pick the winner and write it back to the MDX file in one click. PII masking runs client-side before any data leaves your application, with built-in patterns for email, phone, SSN, and credit cards, plus custom regex. agentmark dev starts a local trace tunnel so you can forward traces from your laptop to the cloud dashboard without touching your SDK config.
Different tools fit different workflows. If you want notebook-integrated observability, Arize. If your team prefers a purely UI-driven workflow with no git involvement, Langfuse will feel more natural.
#LLMOps tools 2026: feature comparison
| Tool | OTEL Native | Prompts/Datasets/Evals in Git | Evals in CI | Self-Host | Agent Tracing | Local Dev | Free Tier |
|---|---|---|---|---|---|---|---|
| AgentMark | Yes | Yes (MDX + JSONL) | Yes | CLI (local) + Data Plane (enterprise) | Yes | Yes (offline) | 20K Spans/Month Free |
| Arize AX | Yes | No | Partial | Yes (ELv2 via Phoenix) | Yes | Yes (Phoenix) | 25K spans/month free |
| Braintrust | Partial | No | Yes | Partial (hybrid) | Yes | No | 1M spans + 10K scores |
| LangSmith | Partial | No | Yes | Enterprise only | Yes | No | 5K traces/month |
| Langfuse | Yes | Partial | Partial | Yes (MIT) | Yes | Yes (self-host) | Free OSS, cloud plans |
#How to actually pick an LLMOps tool
Tables eliminate options. They're bad at making decisions. Here's a better framework.
#Where do your prompts, datasets, and evals live?
If a prompt change breaks production, can you git revert it? Can your teammates review prompt and dataset changes in a pull request before they go live?
If the answer is "I copy-paste from a playground," fix that before you think about observability. The fanciest trace viewer doesn't help if you can't figure out which prompt version caused the problem or which dataset your evals ran against.
The deeper question: can you branch? Can one engineer try a risky prompt rewrite on an isolated branch while another tweaks the dataset, without either change affecting production? In a dashboard, everyone edits the same copy. No isolation, no parallel experiments, no review gate. Fine for 5 prompts. Falls apart at 50.
#Can you develop locally?
Ask whether your tool works on a plane. Can you edit prompts, run experiments against a local dataset, and see traces without hitting anyone's API? If your iteration loop requires a round-trip to someone else's infrastructure, you've added latency to every single change.
AgentMark and Arize (via Phoenix) both work fully offline. Most others require a cloud connection for every edit, eval, and trace view. For a team making dozens of prompt tweaks a day, that round-trip adds up.
#What does tracing actually show you?
Not "does it have tracing." What do you see when an agent fails?
Can you see the full span tree, tool call arguments, branching decisions, and retry logic? Or a list of individual API calls where you reconstruct the story yourself? The difference between those two views is the difference between a 5-minute fix and a 45-minute investigation.
#Do evals block your merges?
If your eval process is "we test manually before big releases," you have a pre-launch checklist, not evals.
Real CI integration means evals run on every PR and fail the merge if quality drops, not as a separate step you remember to run but as a required check in the same panel as your existing tests. AgentMark's GitHub Action does this with two independent gates: an absolute pass-rate floor, and a regression gate that compares each test case against the baseline from the PR's base commit. A prompt change that keeps the overall pass rate at 90% while quietly degrading ten specific cases still fails the build. Failures show up as per-case annotations inline in the PR, the same way jest or vitest failures do.
name: Evals
on: pull_request
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: agentmark-ai/eval-action@v1
with:
api-key: ${{ secrets.AGENTMARK_API_KEY }}
The same output works on GitLab CI and any other JUnit-compatible platform. For agents and multi-step workflows that aren't a single prompt file, the SDK's runExperiment() emits the identical JUnit shape so both show up under one PR check.
#Do you need to be live today?
If you need observability in the next hour, not next sprint, Braintrust and Langfuse are both fast to set up. AgentMark and Arize require more upfront setup. Be honest about your timeline.
#Can you leave?
OTEL trace export? Prompts, datasets, and evals in git or exportable? No proprietary SDK requirement? Can you run experiments locally without a cloud connection? If the answer to any of those is "no," you're accepting lock-in you don't have to accept in 2026.
#Does community size matter for your case?
Langfuse (22,400+ stars) and LangSmith (260M+ ecosystem downloads) have the largest communities in this space. When you hit a weird edge case at 2am, a community that size has probably seen it. If that matters for your team, weigh it honestly.
#What happens when AI tooling fits your workflow
Here's where the workflow question stops being abstract.
Most setups today: notice something in a dashboard. Dig through traces in one tool. Edit the prompt in another. Run evals in a third. Copy it back to your codebase. Deploy. Four tools, six tabs, thirty minutes if you're fast.
Now consider what that looks like when your prompts, datasets, and evals live in git, and your coding agent has access to all of it. Alert fires. You tell your coding agent to find the failing traces, classify why they failed, add the cases to a dataset, fix the prompt, and open a PR. CI runs your evals automatically. You review and merge.
A team with 50 agents pushing weekly updates hits 2,600 agent changes a year. The difference between a thirty-minute fix cycle and an eight-minute one is 950 hours. A full-time engineer spent on fixing, not building.
If you need more than two tabs open to fix a broken agent, your tooling doesn't fit your workflow.
#Where LLMOps tools are headed
The pattern that keeps showing up: the teams shipping reliable agents are the ones whose AI tooling feels like the rest of their dev stack. Same git workflow. Same branching. Same PRs. Same CI. The ones still struggling have a completely separate set of tools and processes for their agents, where changes go live without review and rollback means "does anyone remember what the old version looked like?"
OTEL will keep winning. Data portability will matter more, not less, as teams switch tools. The proprietary lock-in playbooks from the SaaS era work worse when your competitors all support open standards.
I think prompts, datasets, and evals move into the same repo as application code for most serious teams, the way infrastructure-as-code did for ops. I could be wrong about the timeline. I'm not wrong that the tools that survive will be the ones that feel like normal developer tools.
Get started today:
npm create agentmark@latestDocs at docs.agentmark.co.